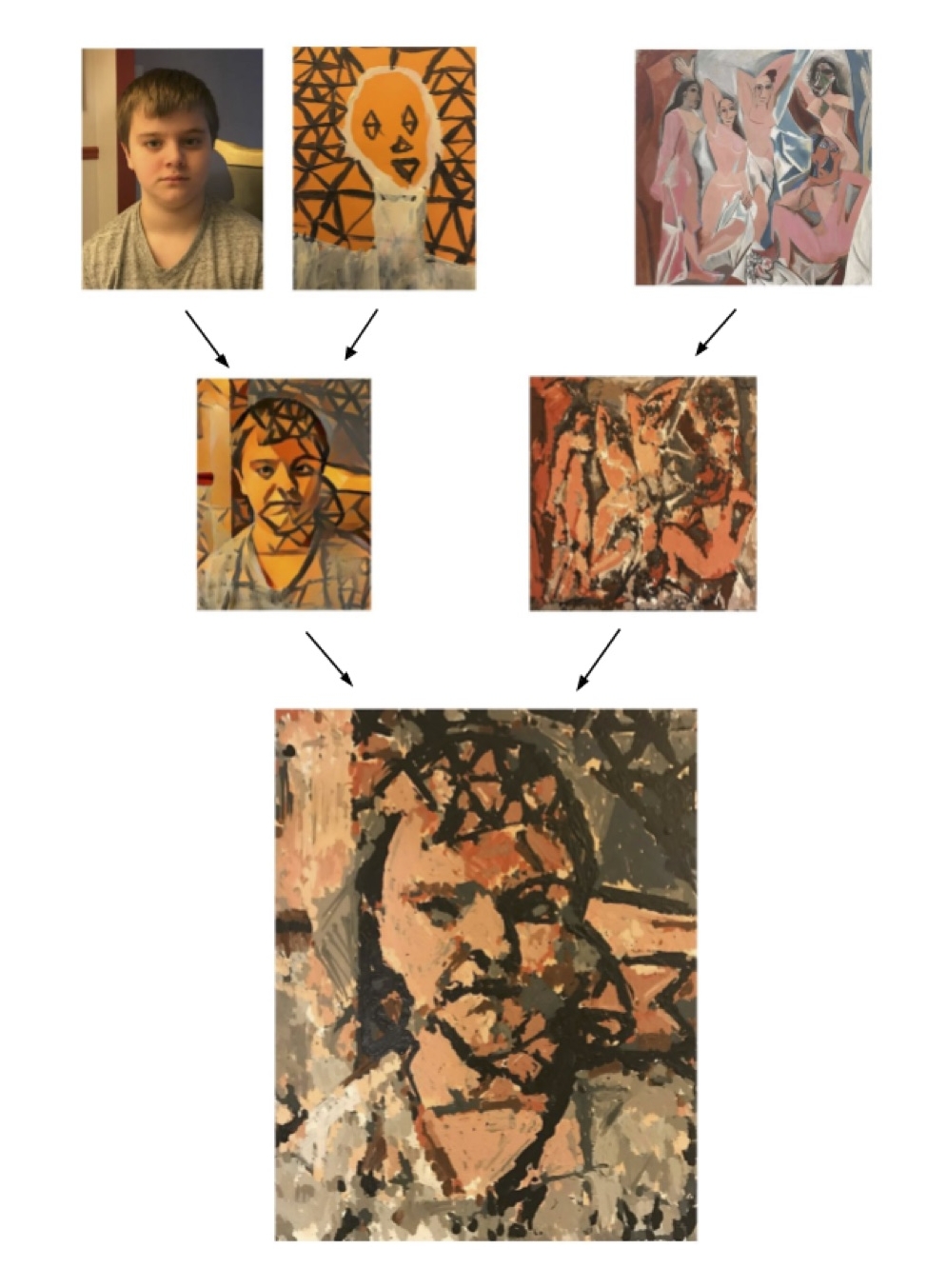
My robots paint with dozens of AI algorithms all constantly fighting for control. I imagine that our own brains are similar and often think of Minsky's Society of Minds. Where he theorizes our brains are not one mind, but many, all working with, for, and against each other. This has always been an interesting concept and model for creativity for me. Much of my art is trying to create this mish mosh of creative capsules all fighting against one another for control of an artificially creative process.
Some of my robots' creative capsules are traditional AI. They use k-means clustering for palette reduction, viola-jones for facial recognition, hough lines to help plan stroke paths, among many others. On top of that there are some algorithms that I have written myself to do things like try to measure beauty and create unique compositions. But the really interesting stuff that I am working with uses neural networks. And the more I use neural networks, the more I see parallels between how these artificial neurons generate images and how my own imagination does.
Recently I have seen an interesting similarity between how a specific type of neural network called a Generative Adversarial Network (GAN) imagines unique faces compared to how my own mind does. Working and experimenting with it, I am coming closer and closer to thinking that this algorithm might just be a part of the initial phases of imagination, the first sparks of creativity. Full disclosure before I go on, I say this as an artist exploring artificial creativity. So please regard any parallels I find as an artist's take on the subject. What exactly is happening in our minds would fall under the expertise of a neuroscientist and modeling what is happening falls in the realm of computational neuroscience, both of which I dabble in, but am by no means an expert.
Now that I have made clear my level of expertise (or lack thereof), there is actually an interesting thought experiment that I have come up with that helps illustrate the similarities I am seeing between how we imagine faces compared to how GANs do. For this thought experiment I am going to ask you to imagine a familiar face, then I am going to ask you to get creative and imagine an unfamiliar face. I will then show you how GANs "imagine" faces. You will then be able to compare what went on in your own head with what went on in the artificial neural network and decide for yourself if there are any similarities.
Simple Mental Task - Imagine a Face
So the first simple mental task is to imagine the face of a loved one. Clear your mind and imagine a blank black space. Now pull an image of your loved out of the darkness until you can imagine a picture of them in your mind's eye. Take a mental snapshot.
Creative Mental Task - Imagine an Unfamiliar Face
The second task is to do the exact same thing, but by imagining someone you have never seen before. This is the creative twist. I want you to try to imagine a face you have never seen. Once again begin by clearing your mind until there is nothing. Then out of the darkness try to pull up an image of someone you have never seen before. Take a second mental snapshot.
This may have seemed harder, but we do it all the time when we do things like imagine what the characters of a novel might look like, or when we imagine the face of someone we talk to on the phone with, but have yet to meet. We are somehow generating these images in our mind, though it is not clear how because it happens so fast.
How Neural Nets Imagine Unfamiliar Faces
So now that you have tried to imagine an unfamiliar face, it is neat to see how neural networks try to do this. One of the most interesting methods involves the GANs I have been telling you about. GANs are actually two neural nets competing against one another, in this case to create images of unique faces from nothing. But before I can explain how two neural nets can imagine a face, I probably have to give a quick primer on what exactly a neural net is.
The simplest way to think about an artificial neural network is to compare it to our brain activity. The following images show actual footage of live neuronal activity in our brain (left) compared to numbers cascading through an artificial neural network (right).